Table of Contents
Function Names
Functions in HiRep need to be implemented for different field or site types, different representations, single and double precision as well as to run on CPU or with GPU acceleration. In order to avoid confusion, functions are named in a coherent matter using the following structure
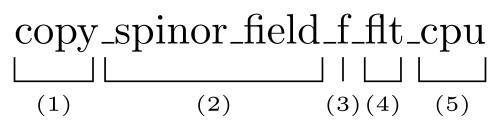
Here, part (1) is the name of the operation performed. Following this is the type of the field structure or site elementary structure that the operation is performed on. (3) then denotes the representation of the structure. f denotes the fundamental representation. (4) indicates, whether the function assume single or double precision. The suffix flt (corresponding to float) denotes single precision , while the omission of this suffix denotes double precision. Finally, the suffixes cpu and gpu distinguish, whether this function operates on an object in the memory of either the host/CPU or device/GPU.
Error Handling
Some standard error handling is implemented in error.h, that prints generic information about what went wrong. CUDA Runtime checking should be done either directly over CHECK_CUDA(call) or after the call has completed with CudaCheckErrors(). MPI calls can be checked using CHECK_MPI(call). Both will log information provided by the respective libraries on what went wrong given the error code, file and function where the error appeared. More tailored error messages can be written directly by using the error function that logs to the standard error output file given at startup.
Usage of Macros
%% TODO there are probably more reasons, expand.
This code relies heavily on the use of macros. There are three different reasons, why macros are used:
- C does not allow overloading functions, but the functions look identical independent of the type, so we declare a macro instead of a function. Typical examples are the macros in
suN.hthat implement operations on elementary site types irrespective of whether they are single or double precision. Therefore, we can use the same macros for example forsuN_vectorandsuN_vector_flt. - Very similar code needs to be implemented many times for different types. This is for example the case when implementing memory, communications or conversion for different field types that only differ in few properties, such as dimension. In this case we write a macro that defines the function. For example, if I wanted to declare the following (useless) function
for all field types not only for the spinor_field, I could write a macro that takes the field type and the elementary site type and invoke the macro for different types directly after.
- The code is for example in a performance bottleneck GPU kernel and needs to be unrolled. A good example here are the macros in
Geometry/gpu_geometry.h, that implement manually unrolled for loops over the components of different elementary site types. This unrolling is crucial to best performance and cannot be avoided, however, unrolling the sometimes over 200 components of the site types directly in the kernels would render the code unmanagable.